在人工智能與大數據深度融合的時代,文本智能技術正成為驅動產業變革的核心引擎之一。達觀數據副總裁賈學鋒,憑借其在文本智能領域的深厚積累與前瞻視野,深入分享了如何將前沿技術轉化為高效、可靠的AI產品與數據處理服務的設計實踐。他指出,成功的AI產品設計不僅是算法的堆砌,更是對業務場景、數據特性與用戶體驗的深刻洞察與系統化工程。
賈學鋒強調,文本智能技術的應用已從早期的簡單檢索與分類,演進到如今的深度理解、生成與決策支持。在設計相關AI產品時,首要任務是精準定義業務需求與價值閉環。例如,在金融風控、法律合規、智能客服等場景中,產品需要能夠處理海量非結構化文本數據(如合同、報告、郵件、對話記錄),并從中提取關鍵實體、洞察風險信號、歸納邏輯關系或生成合規摘要。這要求產品架構必須兼顧技術的先進性與落地的穩健性,確保高準確率、低延遲與可解釋性。
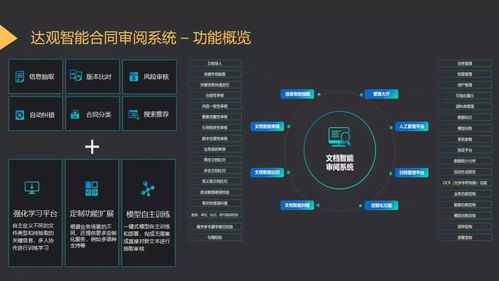
在數據處理服務層面,賈學鋒提出了“數據-模型-應用”三層協同的設計理念。在數據層,需構建專業高效的文本數據預處理與標注體系。面對多源異構的文本數據,服務需提供智能化的清洗、去噪、標準化與增強能力,并結合領域知識構建高質量的標注數據集,為模型訓練奠定堅實基礎。在模型層,應靈活運用預訓練大模型(如LLM)與領域微調技術,結合傳統NLP方法(如規則引擎、統計模型),形成混合智能系統。這種設計既能利用大模型的強大泛化能力,又能通過微調和規則注入確保在特定業務場景下的精準度與可控性。在應用層,產品需提供易用、可配置的API服務或可視化平臺,將復雜的文本分析能力封裝成模塊化功能(如智能審核、知識挖掘、自動報告生成),讓企業客戶能夠低門檻、高效率地集成到自身業務流程中。
實踐中的挑戰與突破同樣關鍵。賈學鋒指出,數據安全與隱私保護是設計時必須恪守的紅線,尤其在處理敏感行業數據時,需采用聯邦學習、隱私計算等技術確保數據“可用不可見”。產品需具備持續學習與迭代的能力,通過反饋機制不斷優化模型,適應語言變化與業務需求演進。降低AI產品的使用門檻,提供清晰的效益度量(如效率提升比例、風險降低指標),對于客戶采納與商業化成功至關重要。
賈學鋒認為,文本智能技術與多模態AI、流程自動化的結合將催生更強大的數據處理服務。AI產品設計將更加注重端到端的智能化解決方案,不僅理解文本,更能關聯圖像、表格等多源信息,并驅動后續的業務行動。達觀數據正致力于此方向的探索,旨在通過創新的AI產品設計與可靠的數據處理服務,助力千行百業實現數字化轉型與智能升級。
賈學鋒的實踐分享揭示了一條清晰路徑:以文本智能技術為核心,通過深度理解業務、精心設計數據流程、構建混合智能系統并聚焦用戶體驗與價值交付,方能打造出真正賦能企業的AI產品與數據處理服務,在數據洪流中挖掘智慧,創造實效。